
Document Processing
Last Updated: Jan 28, 2022
Last Updated: Jan 28, 2022
I need to extract the Invoice Number, date, PO number, and Amount from an invoice.
I am unable to toggle the Invoice number, Invoice Date, and PO number fields to be extracted to proceed.
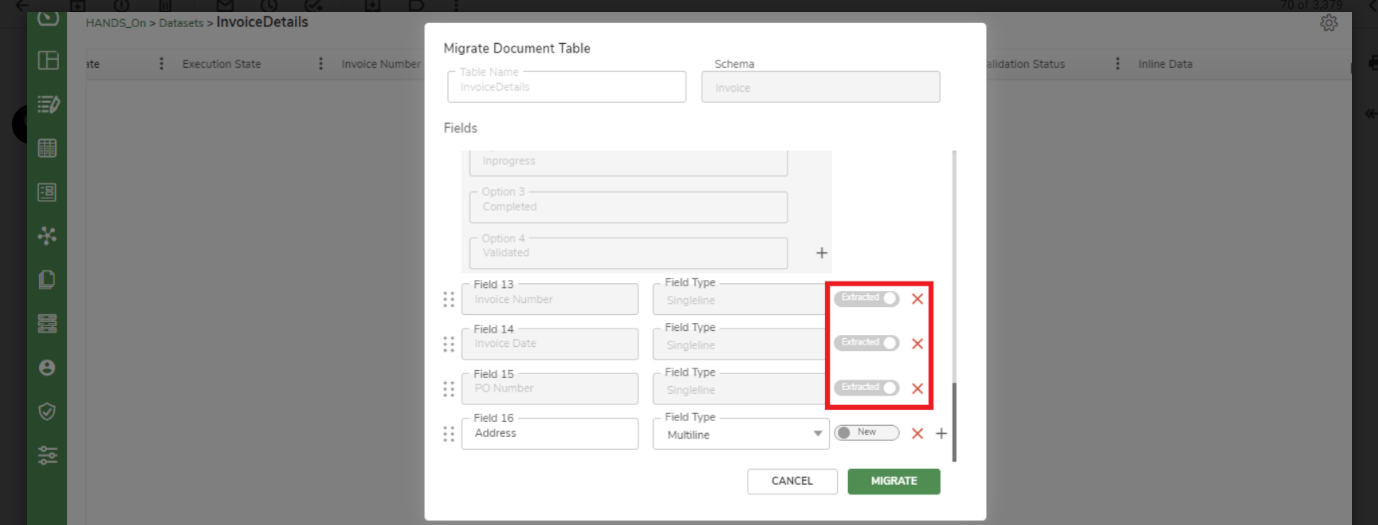 The mentioned columns are predefined columns in the table and are already toggled to Extracted by default. No further actions are needed on the predefined columns.
The mentioned columns are predefined columns in the table and are already toggled to Extracted by default. No further actions are needed on the predefined columns.
After exporting and importing the app, few records from the category table in exported app are missing in the imported app? The documents which are unapproved or deleted in the exported app, before exporting the app, will not be exported and hence those records are missing in the imported app. Base Documents should be present before export. To fix this issue re-train all the deleted documents and approve all the documents which are not approved and then proceed with export-import.
Doc Reader Node is failing with an error –“ ImageToTextPDF has stopped working…….”
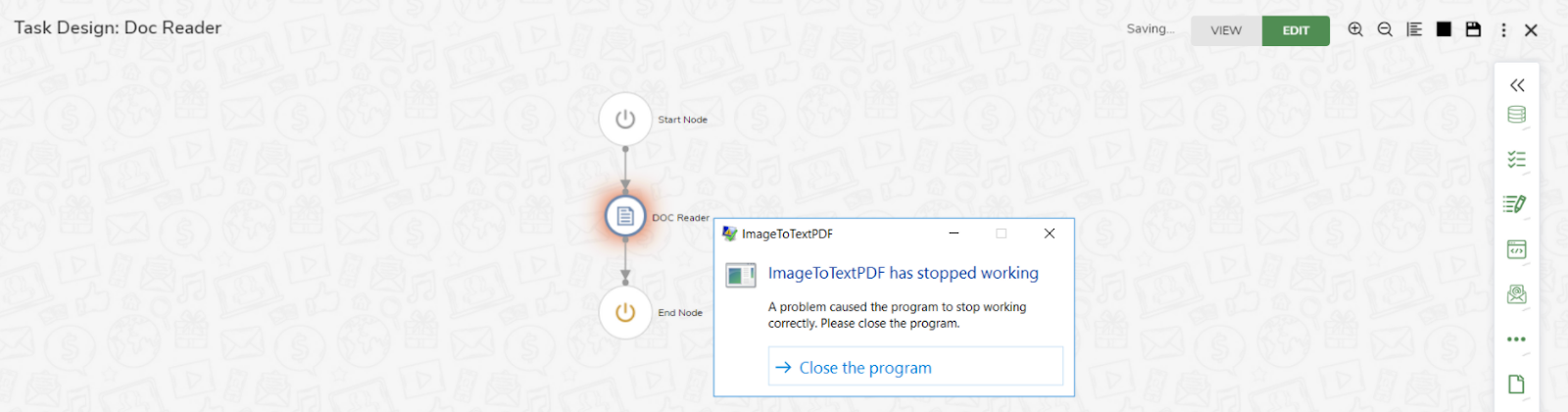 This error occurs when Abbyy trail file does not have the required permission to perform the conversion of images to text pdf.
This error occurs when Abbyy trail file does not have the required permission to perform the conversion of images to text pdf.
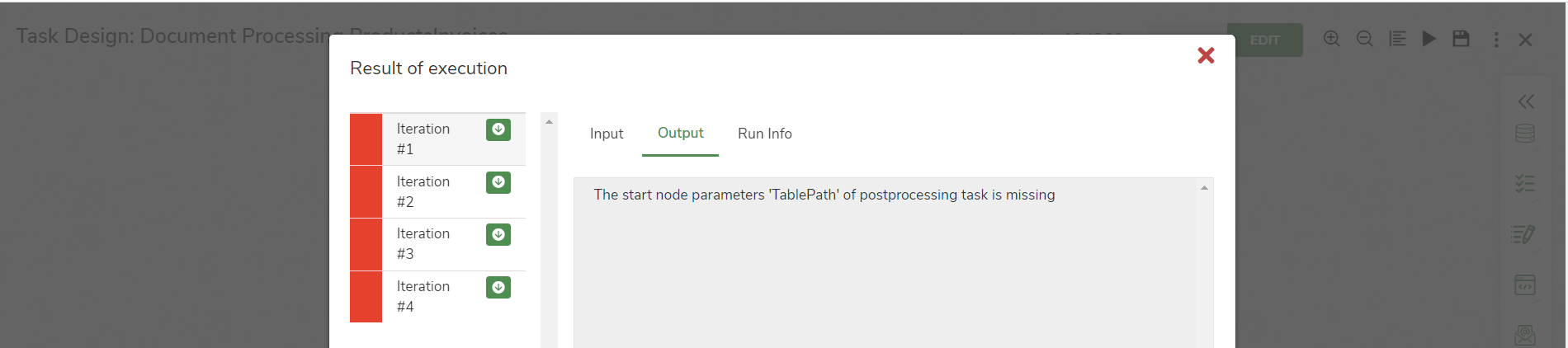 This occurs when Post processing task in Doc Reader properties is selected and in post processing task the parameters in Start Node are either not added or misspelled.
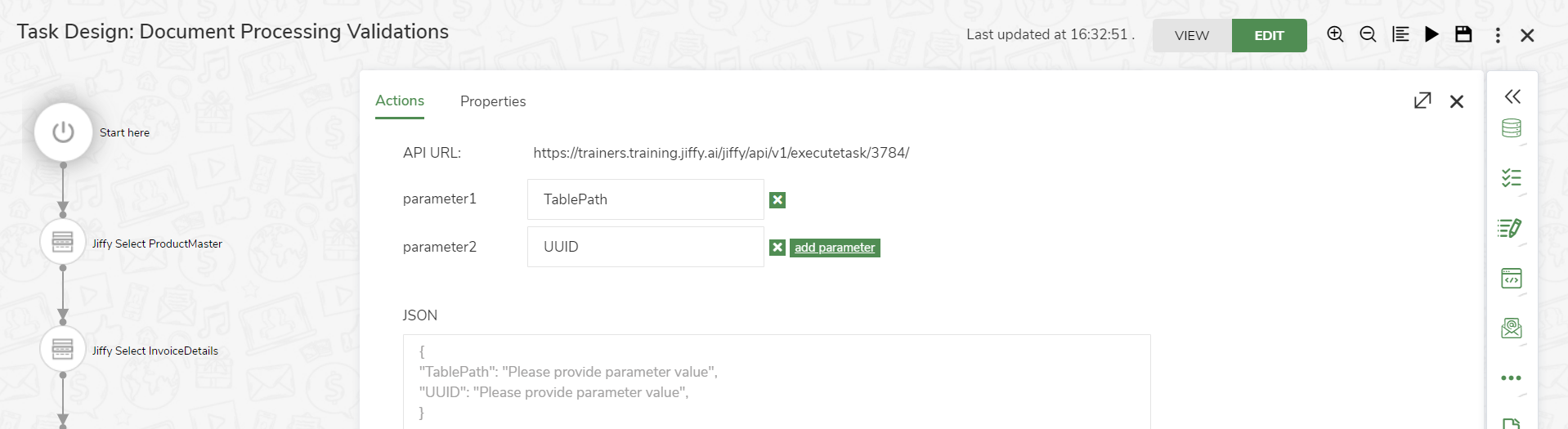
Ensure to give the names of the parameters as UUID and TablePath the same way as shown below.
This occurs when Post processing task in Doc Reader properties is selected and in post processing task the parameters in Start Node are either not added or misspelled.
Ensure to give the names of the parameters as UUID and TablePath the same way as shown below.
Doc Reader Node is failing with an error: “500 Internal server Error. The server encountered an internal error and was unable to complete your request. Either the server is overloaded or there is an error in the application.”
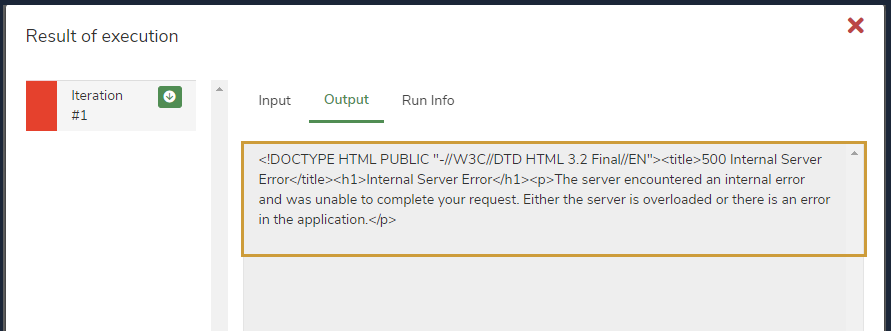 This error may occur if the document passed is an Image-based document and there is no OCR available in the machine to convert image-based documents to text-based documents.
Jiffy can be integrated with OCR tools which convert the image-based document to text-based document.
Follow the steps below:
This error may occur if the document passed is an Image-based document and there is no OCR available in the machine to convert image-based documents to text-based documents.
Jiffy can be integrated with OCR tools which convert the image-based document to text-based document.
Follow the steps below:
I created a Google Cloud account and gave valid credentials. Yet, while executing Handwritten Text Extraction Node I get the error "Invalid Google Credentials".
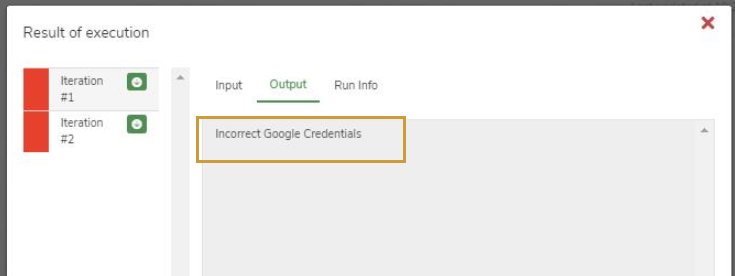 This error occurs when you do not use a paid Google Cloud account. Handwritten Text Extraction Node requires a paid account.
This error occurs when you do not use a paid Google Cloud account. Handwritten Text Extraction Node requires a paid account.
Getting the error "Multiple lines not allowed in Single Line" while familiarizing the document.
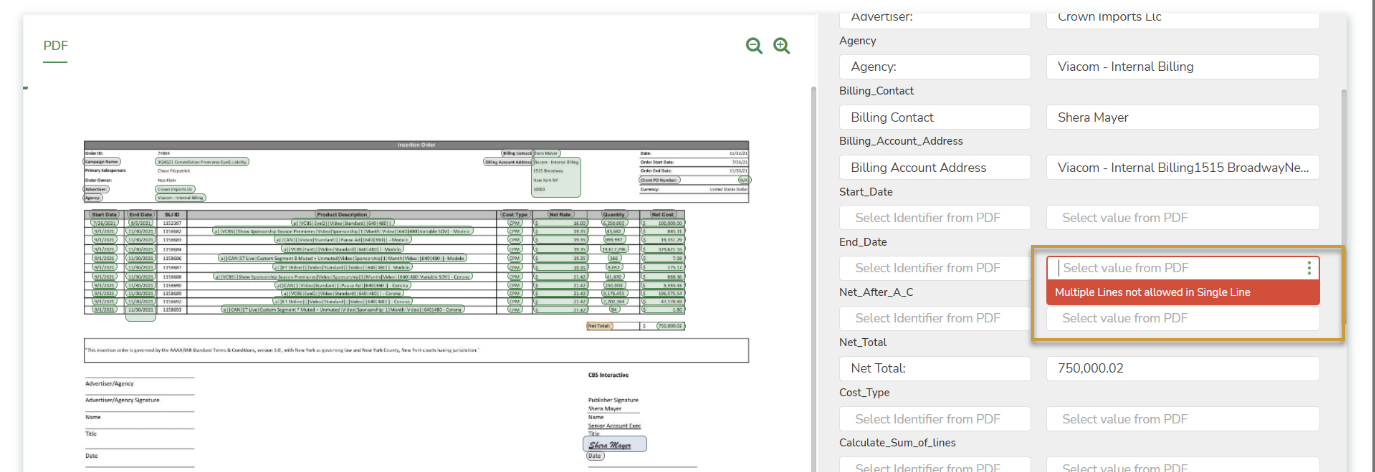 This error occurs when multiple lines of data are familiarized for a Single line field.
Change the Field type of column from Single line to Multiline and familiarize the data again.
This error occurs when multiple lines of data are familiarized for a Single line field.
Change the Field type of column from Single line to Multiline and familiarize the data again.