Additional Options in Document Familiarization Window
Last Updated: Mar 8, 2023
The following additional options are available in document familiarization window. You can use these options based on the document being familiarized.
In scenarios where the field occures:
These additional rules can be specified for extraction, using the Data Capture Rule option.
Click .png) icon against the field in the right panel for which you want to add any additional rules. The Data Capture Rule window opens for that field.
icon against the field in the right panel for which you want to add any additional rules. The Data Capture Rule window opens for that field.
Data Capture Rule for Invoice Date
.png)
Either of the following Data Capture Rules can be applied.
You can choose the occurrence of the data from the drop-down. It can be either First Occurrence or Last Occurrence.
Consider a PDF with ten pages having Total Amount on all pages, the Last Occurrence is selected in the drop-down and the Total Amount on the last page is extracted.
If a document has multiple occurrences of labels that you are extracting, use this option to identify the one to be extracted.
Consider a PDF where the GST Number occurs at multiple places, use this option to extract the desired GST Number which is displayed below the Address.
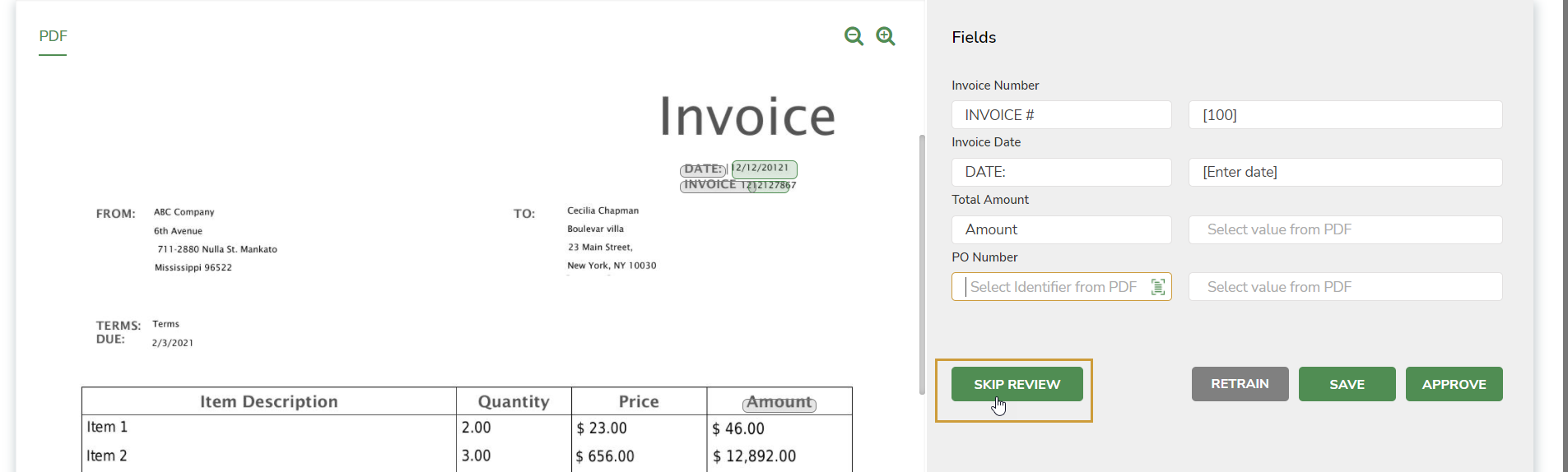
In cases where the document being processed is not of the desired format and you want to skip it from the auto category identification algorithm.
Click the SKIP REVIEW button in the document familiarization window to skip the document training process. All the fields become non-editable.
You choose not to train the Doc Reader for that document and the status is updated to MANUAL_ INTERVENTION_FOR_REVIEW.
There can be multiple resolution for the same type of documents. You may adjust it automatically to the resolution of the base document.
The system saves the resolution details of the base document, for that specific category, as part of the document training process.
If the system fails to adjust the resolution for internal reasons, the document status will be Manual Intervention Validation Failed.
Click the .png) icon and enable the Auto Adjust PDF resolution option to automatically scale the resolution of the current PDF into the base document.
icon and enable the Auto Adjust PDF resolution option to automatically scale the resolution of the current PDF into the base document.
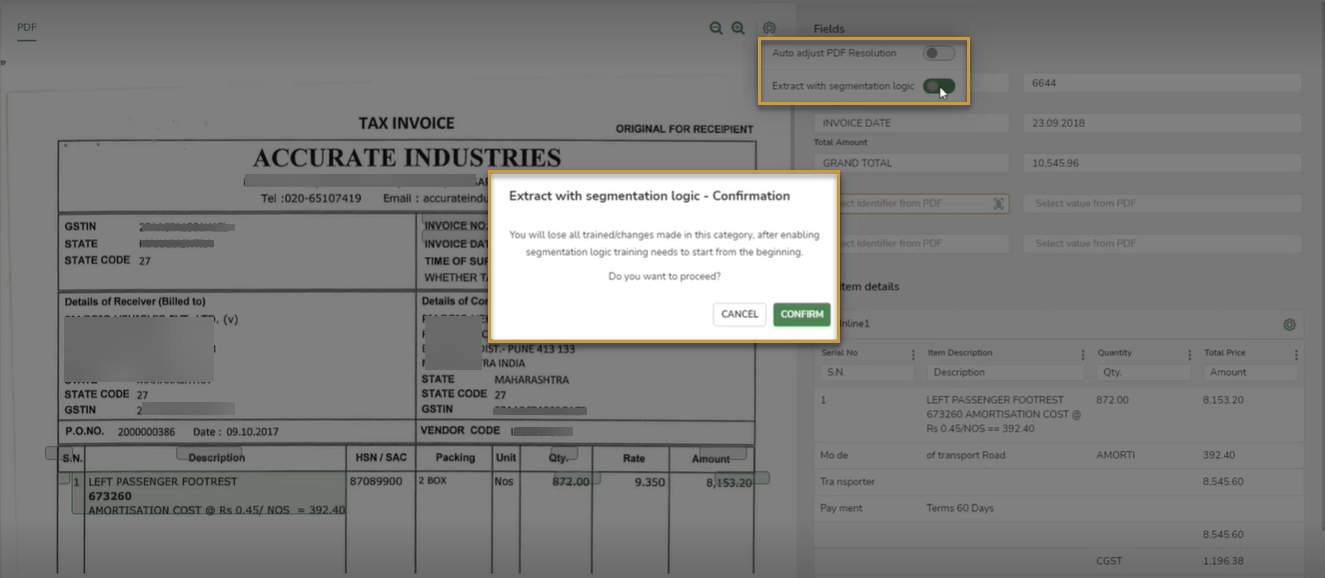
You can select the required words alone during document extraction. All new documents from version 4.8 or above, will follow the word split logic. For example, if you need only Invoice Date to be selected, but the field in the document contains Invoice Date (Shipped to), extraction using new word split logic would be helpful.
All documents trained in the older version will continue in the previous segmentation logic.
You can change to segmentation logic if required, using the Extract with segmentation logic toggle in the icon.
This logic is applicable only for documents in the English language and users must use an area selector.