
Re-Familiarize
Last Updated: Mar 8, 2023
Last Updated: Mar 8, 2023
You can retrain the category when you need to
When the fields are not extracted and if the validation of those extracted fields fails, the status of the record is updated to MANUAL_INTERVENTION_VALIDATION_FAILED in the Post Processing task . You can re-familiarize the document to make the necessary changes to extract those fields.
.png) icon next to the required row with document status as MANUAL_INTERVERNTION_VALIDATION_FAILED, in the Document Table.
The Document familiarization window opens.
icon next to the required row with document status as MANUAL_INTERVERNTION_VALIDATION_FAILED, in the Document Table.
The Document familiarization window opens.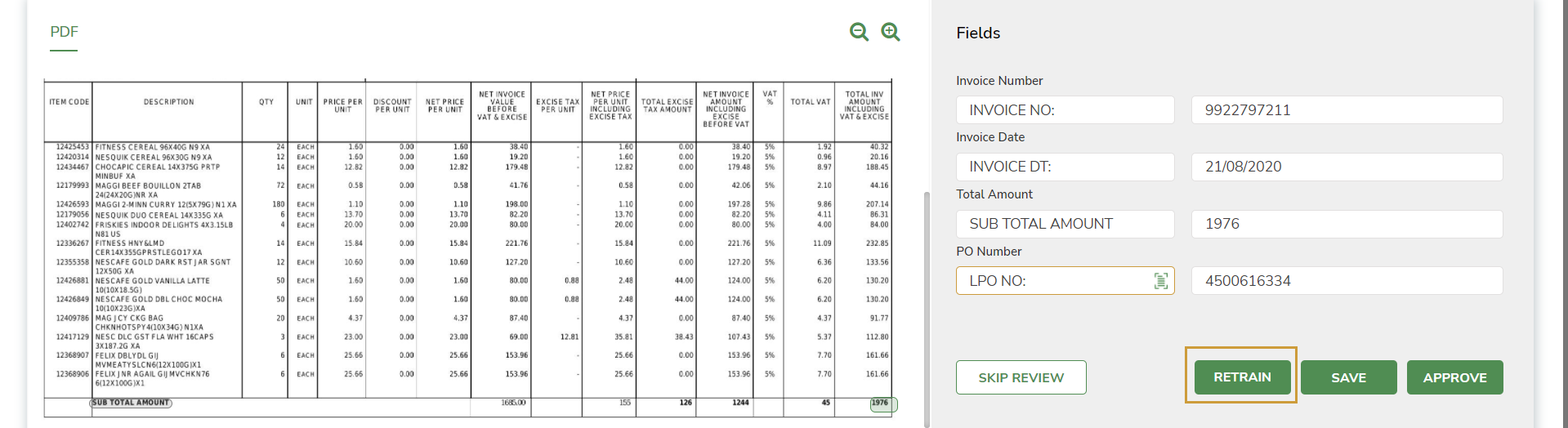
If ML was unable to predict the field in the Document due to change in label, while refamiliarizing select the new label. Next time, when processing same category document, the new label is recognised. Pseudonym Management adds all the probable labels for the fields to be extracted as Pseudonyms to ensure the extraction process covers the probable labels too.
The labels Invoice#, Invoice No., INV Number are used to represent Invoice Number across the different Invoices. All of them must be added as Pseudonyms.
There are two ways to add Pseudonyms.
.png) icon of the Document Table and select the Pseudonym Management option.
icon of the Document Table and select the Pseudonym Management option.
.png)
.png) icon against the Column Name for which you want to add or edit Pseudonyms.
icon against the Column Name for which you want to add or edit Pseudonyms..png)
All the pseudonyms that are added get recorded in the ML dictionary.
When a document of same category is processed, the field with labels matching any of the added Pseudonyms is automatically extracted.
The pseudonym Invoice n0: is added for the column Invoice Number in the Edit Pseudonym field.
If the document has label Invoice n0:, then the field value is automatically extracted as it has been added as a Pseudonym.
.png)
If the status of the record is MANUAL_INTERVENTION_VALIDATION_FAILED , you can correct the fields by selecting the correct label from the PDF in the Document Familiarization window. The re-familiarized label is also added to the Pseudonym list and gets recorded in the ML dictionary.
In earlier familiarization, the label selected was PO No: and in the current document, the label is PO N0: because of which the field was not extracted and validation failed.
When a document of same category is processed again, the field with PO N0: is automatically extracted.
- Refamiliarize the document and select PO N0: in the current PDF.
- PO N0: gets added to the Pseudonym List and gets recorded in the ML dictionary.