
Opendistro to Opensearch Migration
Last Updated: May 8, 2023
Last Updated: May 8, 2023
export JIFFY_INSTALL=“/tmp/jiffy-install/4.10/” mkdir -p $JIFFY_INSTALL/helm cd $JIFFY_INSTALL/helm/ wget –user {username}–ask-password downloads.jiffy.ai/4.10/DeltaUpgrade/jiffy-helms-v4.10.zip
unzip jiffy-helms-v4.10.zip
The snapshot will be pushed to S3 bucket.
Add this role to Kubernetes cluster Service account or grant the worker node role temporary full permissions for S3.
To take snapshots, you need permission to access the bucket. The following IAM policy is an example of those permissions: { “Version”: “2012-10-17”, “Statement”: [{ “Action”: [ “s3:“ ], “Effect”: “Allow”, “Resource”: [ “arn:aws:s3:::your-bucket”, “arn:aws:s3:::your-bucket/“ ] }] }
Depending on the environment AWS Account ID, EKS Cluster ID, Namespace, Service Account Name will change. Before Starting the Activity not down these settings. Trust Relationship Example: { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Federated": "arn:aws:iam::{AWS AccountID}:oidc-provider/oidc.eks.ap-south-1.amazonaws.com/id/{EKS ClusterID}" }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringLike": { "oidc.eks.ap-south-1.amazonaws.com/id/{EKS ClusterID}:aud": "sts.amazonaws.com", "oidc.eks.ap-south-1.amazonaws.com/id/{EKS ClusterID}:sub": "system:serviceaccount:{NameSpace}:{ServiceAccount For Opendistro}" } } } ] }
Check the current opendistro deployments $ kubectl get all -n default Add the new image and tags to the existing Deployment and Statefulset Example of Image Name: "shyamcochin/opendistro-s3:v1" $ kubectl edit -n default statefulset.apps/opendistro-es-1-1633090360-master $ kubectl edit -n default statefulset.apps/opendistro-es-1-1633090360-data $ kubectl edit -n default deployment.apps/opendistro-es-1-1633090360-client Examples: image: docker.io/{DockerHubID}/opendistro-s3:v1 It will automatically recreate the pods
Go to Kibana console => Select Dev Tools.
GET /_cat/plugins Output: opendistro-es-1-1633090360-master-0 repository-s3 7.10.2 opendistro-es-1-1633090360-data-0 repository-s3 7.10.2 opendistro-es-1-1633090360-client-84679488bd-7wpj4 repository-s3 7.10.2
Connect to core server stop the td-agent $ systemctl stop td-agent Backup the existing td-agent configuration file $ cp td-agent.cont td-agent.conf.{Date}
Go to Kibana console => Select Dev Tools
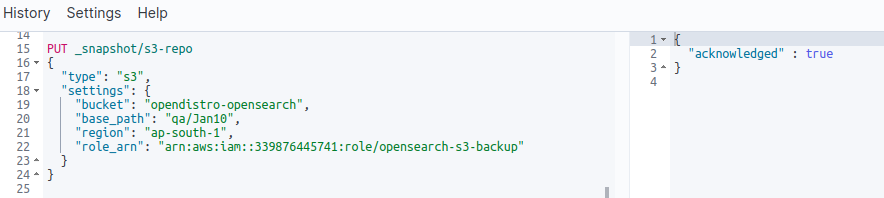
PUT _snapshot/s3-repo { "type": "s3", "settings": { "bucket": "opendistro-opensearch", "base_path": "
", "region": "ap-south-1", "role_arn": "arn:aws:iam::339876445741:role/opensearch-s3-backup" } }
Output: { "acknowledged" : true }
Go to Kibana console => Select Dev Tools
Take snapshot As per the environment change the indices name. Example “demo3* => “jiffy” PUT _snapshot/s3-repo/1 { “indices”: “demo3”, “ignore_unavailable”: true, “include_global_state”: false, “partial”: false } OR PUT _snapshot/s3-repo/2 { “indices”: “,-.opendistro”, “ignore_unavailable”: true, “include_global_state”: false, “partial”: false }
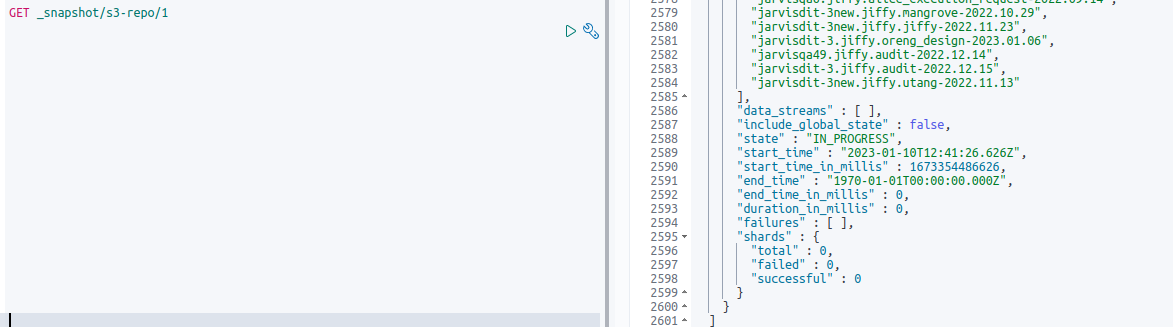
Check the Snapshot status:
GET _snapshot/s3-repo/1
State is: IN_PROGRESS
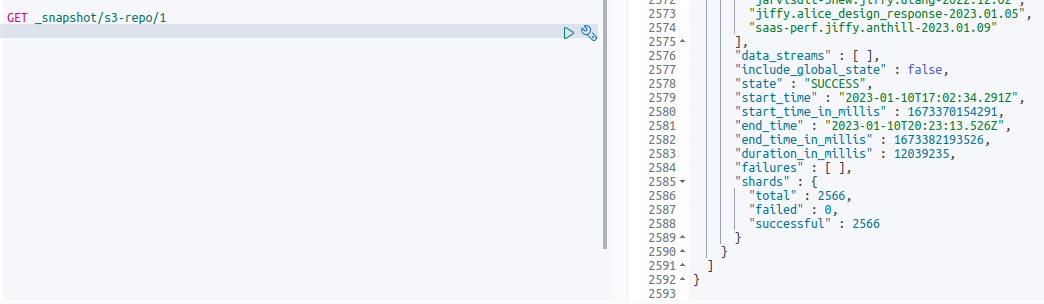
State is : SUCCESS
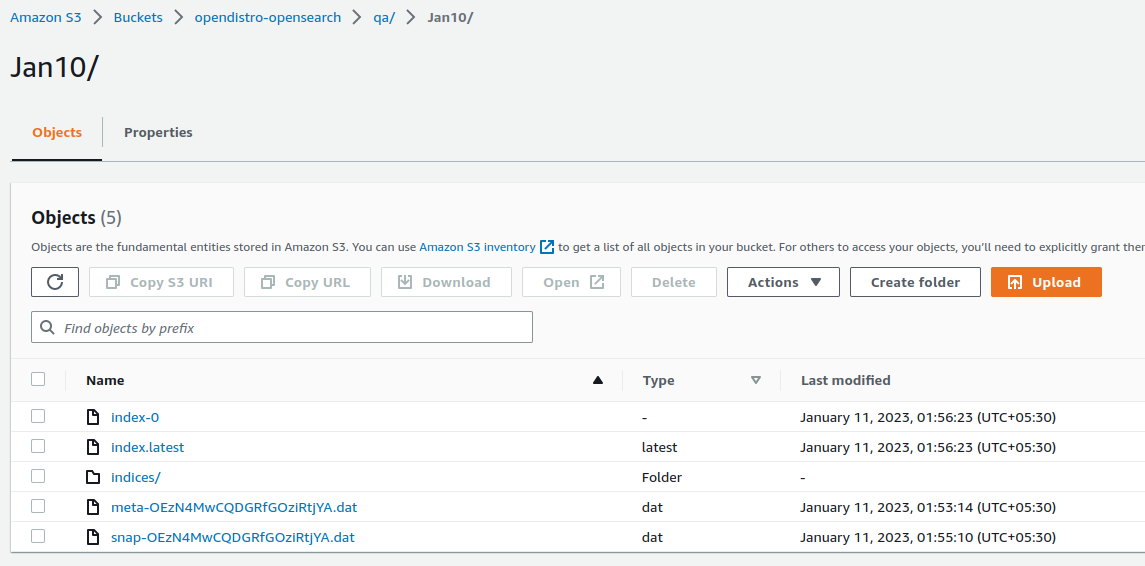
To verify the all snapshots are backup to S3 bucket.
Opensearch and Dashboards deploying via helm chart. Clone the repository from bitbucket.
Opensearch Repository $ git clone git@bitbucket.org:jiffy_bb_admin/efk.git $ cd chart
Create a New Namespace for Opensearch:
Create Namespace for opensearch $ kubectl create namespace opensearch
Modified the values.yaml file as per the requirement and below mentioned options are required. Based on the environment this may change.
Go to opensearch folder $ cd opensearch Replicas replicas: 2 Custom Image Name image: repository: "jiffyai/opensearch_s3" tag: "v1" Java Heap Memory Settings opensearchJavaOpts: "-Xms2048m -Xmx2048m" Resourse Limits resources: requests: cpu: "1000m" memory: "800Mi" Persistent Volume as per requirement persistence: enabled: true size: 250Gi Disable Ingress Controller in this steps ingress: enabled: false
Deploy the opensearch with helm.
Deploy Opensearch using Helm, without enabling ingress. $ cd charts $ helm install -n opensearch opensearch opensearch/ -f opensearch/values.yaml Check the opensearch deployments $ kubectl get all -n opensearch $ kubectl get ing -n opensearch
Before enabling ingress, rename the existing opendistro ingress hostname.
Example "cluster.demo.jiffy.ai" to "test.demo.jiffy.ai" $ kubectl get ingress -n default $ kubectl edit ingress {Ingress-Client-Name} -n default $ kubectl edit ingress {Kibana-Client-Name} -n default
Enable ingress for opensearch. Based on the environment this configuration may change, like hosts.
Enabling ingress $ cd charts $ helm upgrade -n opensearch opensearch opensearch/ -f opensearch/values.yaml Check the Ingress $ kubectl get ing -n opensearch
Deploy the opensearch-dashboard using with helm.
Modify the opensearch-dashborad value.yaml file.
Go to Opensearch-Dashboard folder Disable Ingress Controller in this steps ingress: enabled: false
Deploy Opensearch-Dashboard $ helm install -n opensearch dashboard opensearch-dashboards/ -f opensearch-dashboards/values.yaml Check the details $ kubectl get all - opensearch $ kubectl get ing - opensearch
Enable the Ingress for Opensearch-Dashboard. Based on the environment this configuration may change, like hosts.
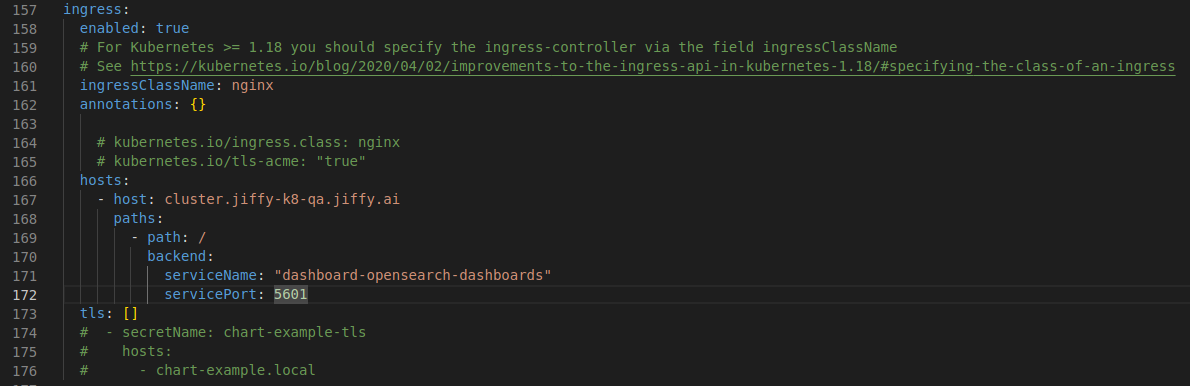
Enable ingress for Opensearch-Dashboard $ helm upgrade -n opensearch dashboard opensearch-dashboards/ -f opensearch-dashboards/values.yaml Check the ingress $ kubectl get ing - opensearch
First register the S3 repository using below command.

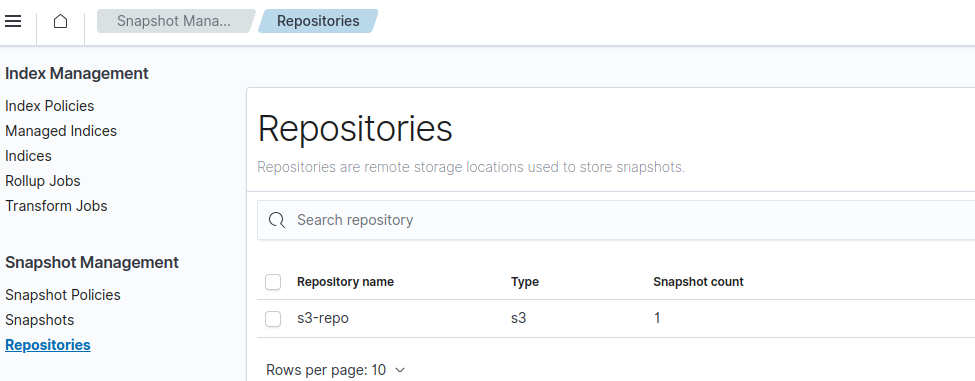
After enabling S3 repository you can see the snapshots.
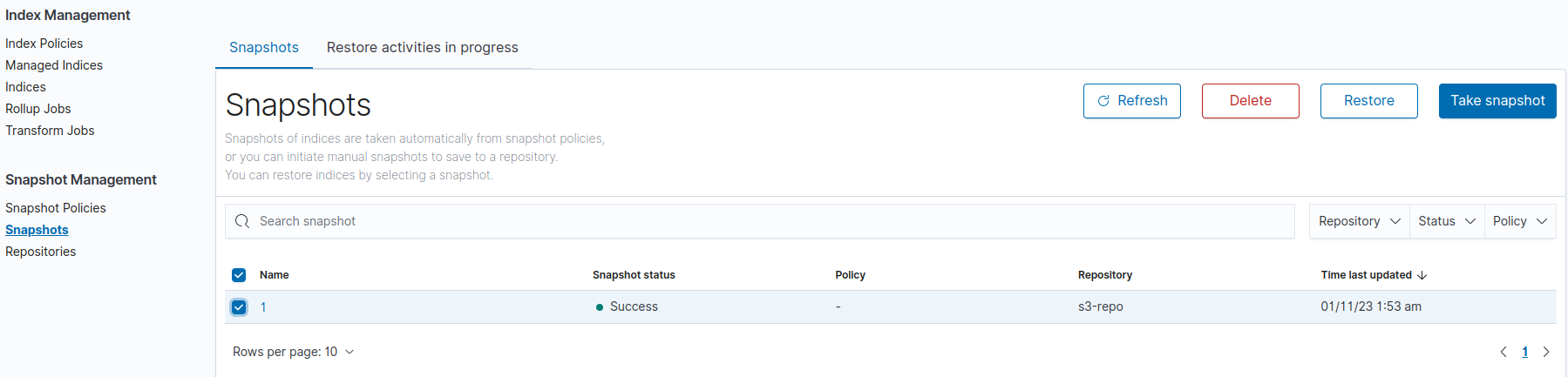
Restore the snapshots.
Go to the Snapshot Management => select the snapshot => click on restore button =>
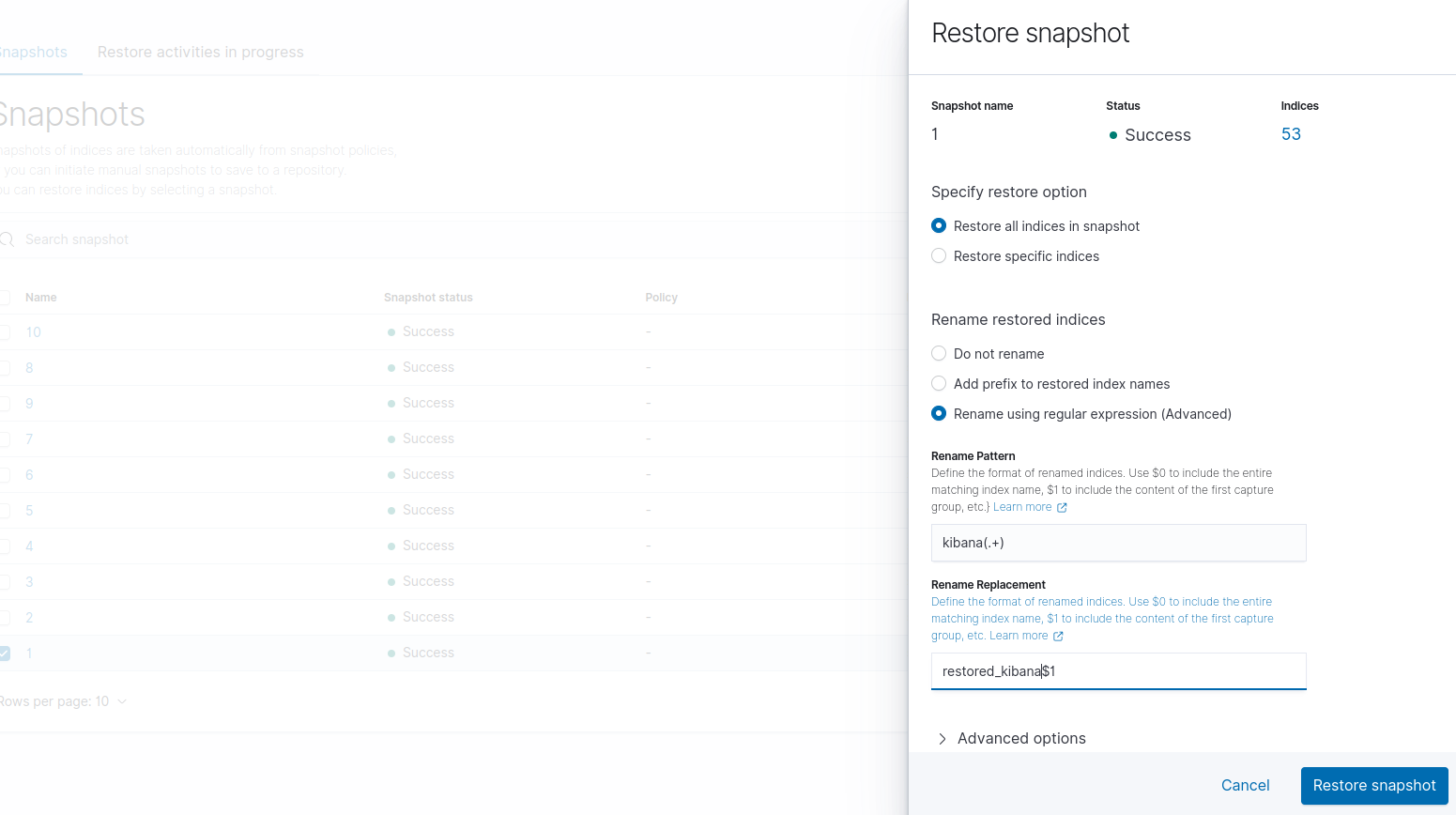

Before start the activity, note down the all index names like ns-jarvisdit*
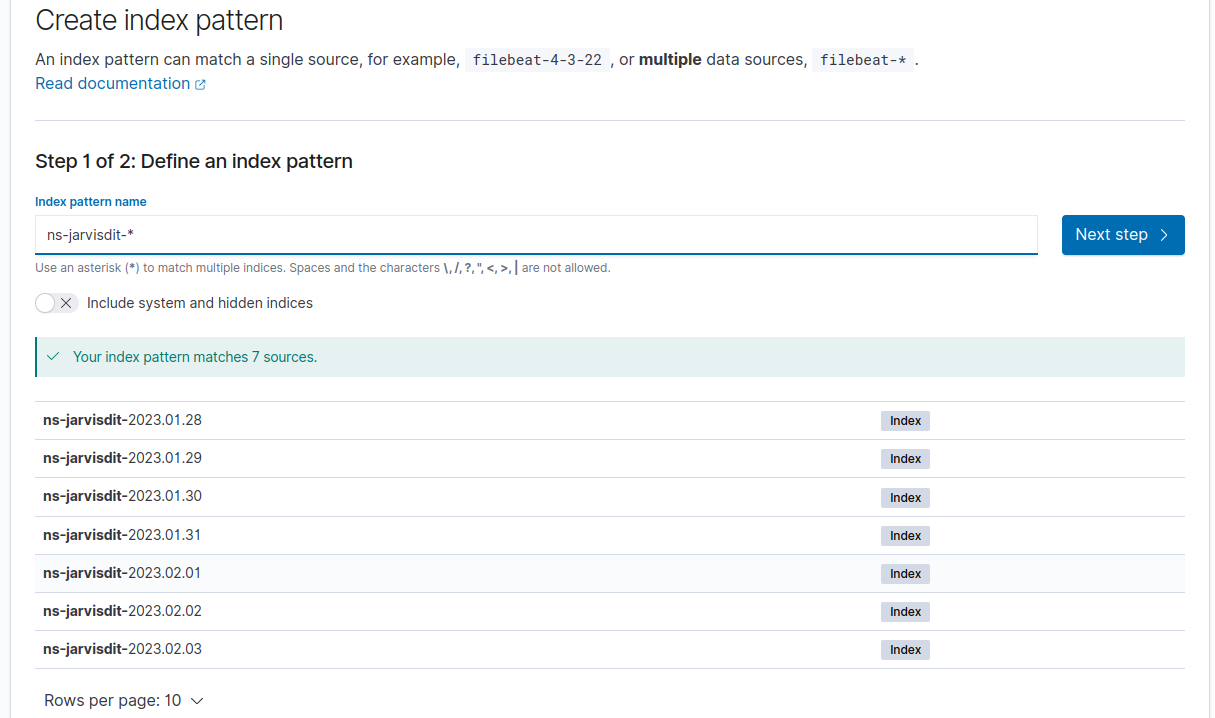
Go to Stack Management => Create index pattern.
Index pattern name : ns-jarvisdit*
Connect to the core server and backup the existing td-agent.con file. To check the existing Td-aget version and update.
Check the Current Version $ rpm -qa | grep td-agent $ td-agent --version Update to new version $ yum install td-agent $ systemctl daemon-reload $ systemctl restart td-agent
Install the Opensearch Plugin
$ td-agent-gem install fluent-plugin-opensearch $ td-agent-gem list | grep fluent-plugin*
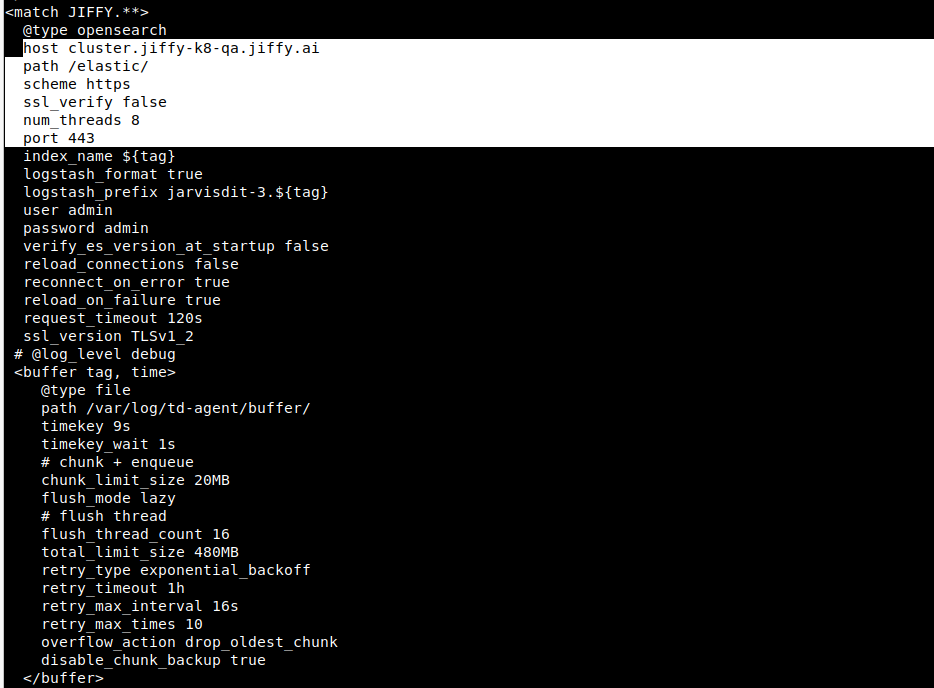
Path: /etc/td-agent/td-agent.conf
Update the Type, Host, Path, Port
 Restart the td-agent service.
Restart the td-agent service.
systemctl restart td-agent systemctl status td-agent For checking Logs $ tail -f /var/log/td-agent/td-agent.log
Modify the fluentbit settings using helm. Update the new opensearch endpoint and namespace with the following output example.
values.yaml:
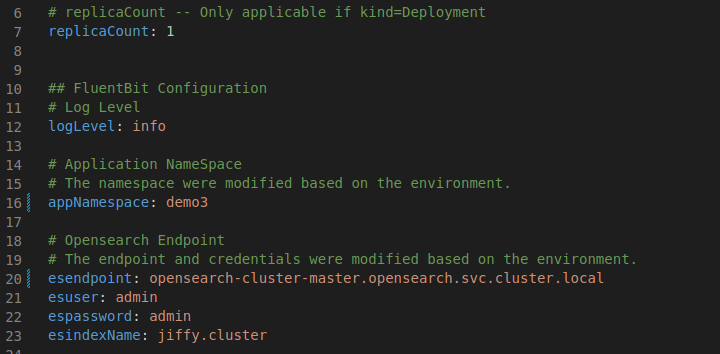 values-fluentbit.yaml:
values-fluentbit.yaml:
outputs: | [OUTPUT] Name opensearch
Match kube.* Host {{ .Values.esendpoint }} Port 9200 HTTP_User {{ .Values.esuser }} HTTP_Passwd {{ .Values.espassword }} TLS On TLS.VERIFY Off Logstash_Format On Index {{ .Values.esindexName }} Logstash_Prefix {{ .Values.esindexName }} Replace_Dots On Retry_Limit 5 Buffer_Size 10MB Suppress_Type_Name On
As per the requirement add the shards values: PUT /_cluster/settings { “persistent” : { “cluster.max_shards_per_node” : 7000 }, “transient” : { “cluster.max_shards_per_node” : 7000 } } Check the status: GET _cluster/settings
GET /_cat/plugins GET _snapshot/_all GET _cat/indices?v GET _cat/allocation?v GET _cluster/state GET _cluster/settings
After migration to opensearch, scale down the opendistro deployment and stateful sets to zero, which can be deleted later if no issues are observed.